複数の企業から調達している部品であっても、同じ地域に工場が集中している場合、地震や水害などでサプライチェーンの維持に大きな影響が生じることがありますが、部品と製造拠点を結びつけるデータは少ないのが実情です。そこで、日立製作所 研究開発グループでは、サプライチェーンのリスク低減を目的としたディープインサイト推定技術を開発し、企業情報やISO認証情報などのオープンデータから、部品の製造拠点を推定できるようにしました。松田知紘研究員と、水品圭汰研究員に、サプライチェーンリスク低減の意義と、工場推定の難しさを乗り越えた技術開発、利用者を想定したアプリケーション開発の歩みについて聞きました。
デジタルオブザーバトリ(Digital Observatory)で2人の研究者が再会する
松田:大学ではいろいろと幅広く学べるように電気電子情報通信工学科を選びました。学部や大学院では電磁波の研究をしましたが、将来にわたって電磁波をずっと研究し続けることには違和感がありました。そんな状況の中で就職活動中に日立と出会い、実に幅広い分野を手掛けている企業であることを知りました。研究テーマを変えたいと思った場合でも、違う分野のテーマにチャレンジできるはず、と期待して入社を決めました。

日立製作所 研究開発グループNext Researchデジタルオブザーバトリプロジェクト 研究員・松田知紘
最初にネットワークを研究する部署に配属されました。そこでは携帯電話の通信品質を改善する技術開発などで事業貢献してきましたが、全社的なビジネスの統廃合などにより担当する研究分野も変わり、次にロボットの開発に5年ほど携わりました。その後はビル関係や工場のIoT関係のデータの収集・活用に関わる研究を重ね、2025年からはデジタル情報を観測するデジタルオブザーバトリ(Digital Observatory:デジタル観測所)、すなわち、データ観測に基づく社会リスクの把握、予兆発見の研究に取り組み始め、現在に至っています。
日立では、本気で手を挙げれば従来の業務と異なる分野であっても挑戦させてくれる文化があります。そういう意味では仕事にモチベーションを持ちやすいですし、違うことにチャレンジしやすい風土があります。日立で飽きることなく仕事を続けられている理由の一つがここにあることは間違いないですね。
水品:私は実は松田さんと同じ大学・学科の出身で、松田さんがリクルーターだったことから入社前からのお付き合いがありました。学生時代は半導体分野で、NAND型フラッシュメモリーのエラーパターンの解析や誤り訂正の研究をしていましたが、大学院に進学したころ、ディープラーニングによる画像認識が盛り上がっていて、コンピュータービジョンと半導体の架け橋による産業応用の面白さに魅力を感じ、民間企業で研究者として働きたいなと思い始めました。日立への入社のきっかけは、松田さんから直接声をかけられたからではありますが、その他にも先輩が多く就職していたこともありますし、日立の事業領域の広さやそこから生まれるケイパビリティの広さに感銘を受けたことも決め手になりました。さらに自分の研究結果が現場に適用されるところを見たいという興味もあり、日立で働くことにしました。

日立製作所 研究開発グループNext Research デジタルオブザーバトリプロジェクト 研究員・水品圭汰
入社当初はデータ分析を担当しました。医療品製造機器の故障を予知するために、エラーパターンを分析する業務です。研究結果は、実際のPoC(概念実証)につながる成果に結びつきました。その後、現実とデジタルをつなぐ「コモングラウンド」の研究に従事し、現実空間と仮想空間を緊密に連携させた現実空間とデジタル空間がリアルタイムに連動して相互に作用しあうアプリケーションの開発を手掛けてきました。
その後、デジタルオブザーバトリ研究推進機構の立ち上げに伴い、東京大学との連携によるデジタルオブザーバトリのプロジェクトに共同研究員として関わらないかとお声がけいただき、参画することになりました。同大学との連携はグローバルを見据えてさまざまな分野にデジタルオブザーバトリを適用できるはずと考え、期待に胸を膨らませていたことを今でもよく覚えています。
リスクになりそうな情報を可視化してインサイトを抽出
水品: 東京大学が「デジタルオブザーバトリ研究推進機構」を設置したのは2023年4月です。デジタルオブザーバトリとは、多様な社会・経済活動をデジタルデータとして観測可能にすることで、自然災害や気候変動によるリスク予兆の早期発見や、リスクへの対処策を導き、復旧や回避などのアクションを起こせるようにするものです。ニュースやソーシャル情報、統計情報などから、どのような事象が原因になって何にダメージを与えているのかを予測します。
日立も社会インフラ基盤に多く関わる中でデータマネジメント基盤の研究にも取り組んできた企業です。そのため、特に本共同研究では「サプライチェーンのレジリエンス向上」に注力しようと考えています。
経済産業省が「デジタル時代のグローバルサプライチェーン高度化研究会 」でサプライチェーンのリスクについて議論するなど、近年ホットな領域として注目されているので、サプライチェーンマネジメント領域で事業を展開する事業部も巻き込んで研究を推進するのが効果的と考えました。

サプライチェーンリスクとしては、地震や洪水などの自然災害や、パンデミック、港湾のストライキや人権リスクなどが様々考えられます。例えばある河川が氾濫した場合、その流域の工場が稼働停止するとサプライチェーンに影響を及ぼします。そのインサイト(洞察)を得るためには、地理空間に点在するリスクと自社のサプライヤーの所在地とを照合する必要があるのです。どの地域にどんな製品を供給している工場があるかを把握し、リスクの情報と突き合わせることでリスク評価ができるわけです。
ただし、実際のサプライチェーンではサプライヤーの地理空間情報、すなわち工場の場所などの情報が集められないことがほとんどです。製品を供給する企業の情報を調べても、東京都中央区、東京都港区といった本社所在地の情報だけで、実際に部品を作っている工場についての情報はわからないことが多い。さらに、商社などを通じて購入している部品については、メーカーに直接確認することができないこともあります。これまでは、地理空間の情報を調達担当者がメーカーに直接確認することでリスクと照合するほかありませんでした。この労力を減らして一部を自動化できれば調達担当者が本来の業務に集中できるということが、現場のヒアリングから見えてきた事実です。

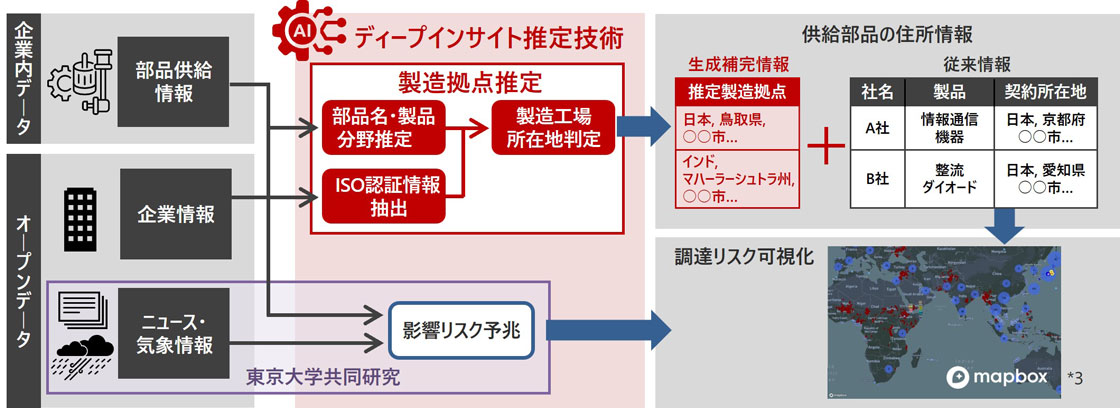
1つの製品を作るには、数千種類の部品が使われます。自社で数百種類の製品をラインアップしていたら、数千×数百という膨大な部品がサプライチェーンで調達されています。これを調達担当者が電話などをかけて調べるわけです。一度所在地情報を収集した完全なデータを作成しても、製品改良や部品の生産中止に伴う製造工場の変更などがあり、調査はイタチごっこになります。そこで日立が部品の製造工場の「所在地を推定する」システムを提供し、情報収集を自動化できるようにしました。ここでは多様なデータを元に人間が想定しきれないインサイト(洞察)を抽出する「ディープインサイト推定技術」を用います。
6割程度に高めるだけでも業務は大幅に効率化する
水品:開発した技術の最終的なゴールは、「どこの会社から何を買っていて、どこで作っているのか」を高い精度で推定することです。企業内では部品供給元の情報を保有していますが、契約情報は本社所在地が記載されており、実際に部品を製造している工場の場所は分かりません。実際のデータを確認すると、工場の場所の情報は3割程度しか把握できていないのが現実です。調達担当者へのヒアリングにより、これが6割程度まで高められれば業務は大幅に効率化できるということがわかりました。そこで私たちは、ディープインサイト推定技術によって、企業情報や認証情報といった公開情報を使って、部品の製造工場を推定できるようにしました。
製造業のサプライチェーンリスク低減の全体像
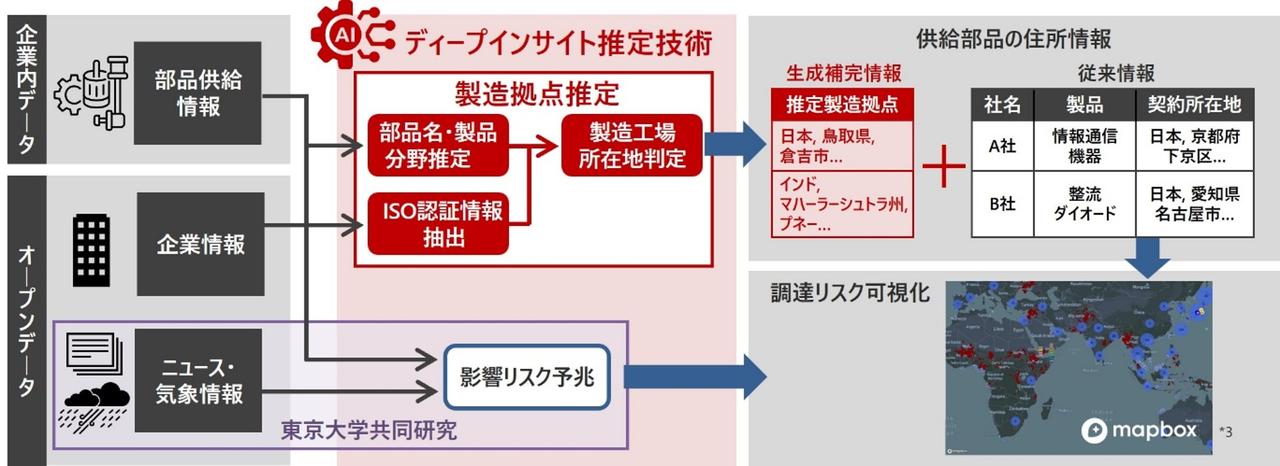
まず企業情報として、企業のホームページなどに工場や物流拠点などの事業所の情報が掲載されています。ただし、その形式は、テキスト、PDF、画像や地図アプリ上にピンなど、企業ごとにまちまちです。さまざまなパターンの非定型情報から、工場の住所や製造品種などに分類した定型情報に加工するために、特徴のある大規模言語モデル(LLM)を採用することで、精度を高めることに成功したと思います。
一方のISO認証情報は、品質マネジメントに関する国際資格であり、一貫した製品・サービスの提供を実施する能力を有することを示すもので、企業は積極的に公開しています。例えば、認証を取得している事業所、製造する製品の種別などの情報が明らかになっています。ただし、記述内容はISOで決まっているものの、書式は定まっておらず、従来の自然言語処理では情報を構造化できませんでした。LLMを使い、各社でバラバラな内容を統一した形に整理(構造化)することで、部品と工場の関係をオープンデータから導けるようにしました。
もう1つ生成AIを活用した部分があります。それが、調達情報に記された部品名と、ISOの情報の突合です。部品情報は、調達担当者がわかるように管理されていて、例えばH鋼、スクリュー、アルミニウム鋼材など部品の名称が記載されています。一方でISO認証の情報は、ある事業所が取得した事業所の主たる機能、例えば「製鉄」や「組立」のような粒度で記載されており、情報の粒度の違いがあるのです。さらに同じ部品であっても会社ごとに名称が異なることも珍しくありません。そこで、体系的に整理されたコード体系に一旦マッピングすることで、どの部品がISOのどの製品コードに対応するのかを整理します。しかし、LLMは部品名とコード体系をマッピングする知識は持っていないため、LLMをファインチューニング(追加学習)します。これにより、部品名とISO認証情報の粒度を揃えることでデータ同士の突合が可能になり、工場の所在地の推定に役立てられる、というわけです。
ディープインサイト技術における製造拠点推定の方法
ディープインサイト推定技術では、「推計製造拠点の候補」を提示します。調達担当者は調達先の企業や部品に対して非常に深い知識と経験を保有しているため、複数の候補を提示して調達担当者の知見と組み合わせることで、人間とLLMが協調して高精度な推定を可能にします。また、調達担当者の選択履歴や傾向を蓄積することで、使うほどに賢くなるシステムになっています。
これらのディープインサイト推定技術をはじめとした研究開発の内容をまとめた論文は、「The 8th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery」に採択される成果も得ることができました。
現場の運用から知見を得て賢く、安全に使えるAIを開発
水品:技術開発だけでなく、現場で使ってもらうための工夫もしています。推定に用いるLLMはローカルで完結する仕組みとすることで、機密情報であっても安心してシステムに入力してもらえるようにしています。外部のAIモデルを使うことによるセキュリティ・リスクを考慮したためです。日立はIT,OTに加えてモノづくりの現場が社内にあり、社内に各分野のスペシャリストが多数在籍しています。システムは使ってもらって初めて価値があります。システムは安全であり、使うことで賢くなっていくことを示すことで、現場の優れた知見を蓄積することが可能になると考えています。
もう1つ、再現性の担保も考慮しています。オープンなAIモデルは新しいモデルが次々に登場し、同じ入力でも回答内容が変化する可能性があります。一方、推計製造拠点の候補を提示するシステムでは、同じ質問に対して同じ回答が得られる必要がありました。そのため、複数のAIエージェントが相互に入出力を監視しており、一定の回答品質を担保するように設計しています。
この推定技術の開発に着手した2023年頃にはまだ複数のAIエージェントが協調して動くエージェンティックAIのフレームワークがなかったので、AI同士が協調する仕組みを手作りして回答の質を担保するようにしました。
こうした技術の組み合わせにより、日立グループ内の調達部門の情報を使ったケースで85%を超える精度でサプライヤーの製造拠点情報を推定できることが実証できました。これはグループ内のデータを用いたものであり、サプライヤーの製造拠点の「正解」がわかっていることから高精度が確認できたものではありますが、共同研究を行っている東京大学からは、「こんなに高い精度でデータが推定できるとは予想していなかった」というポジティブな評価をいただきました。
リスク対策のアプリケーションと融合を図る
松田:水品さんが開発した製造拠点の推定技術では、データが数字と文字で提示されます。ただしこの推定技術を調達部門などの現場で使えるようにするためには、GUIや情報の根拠の見せ方など、アプリケーションとしてさらに工夫する必要があります。そうしたアプリケーションの開発は、私が担当してきました。
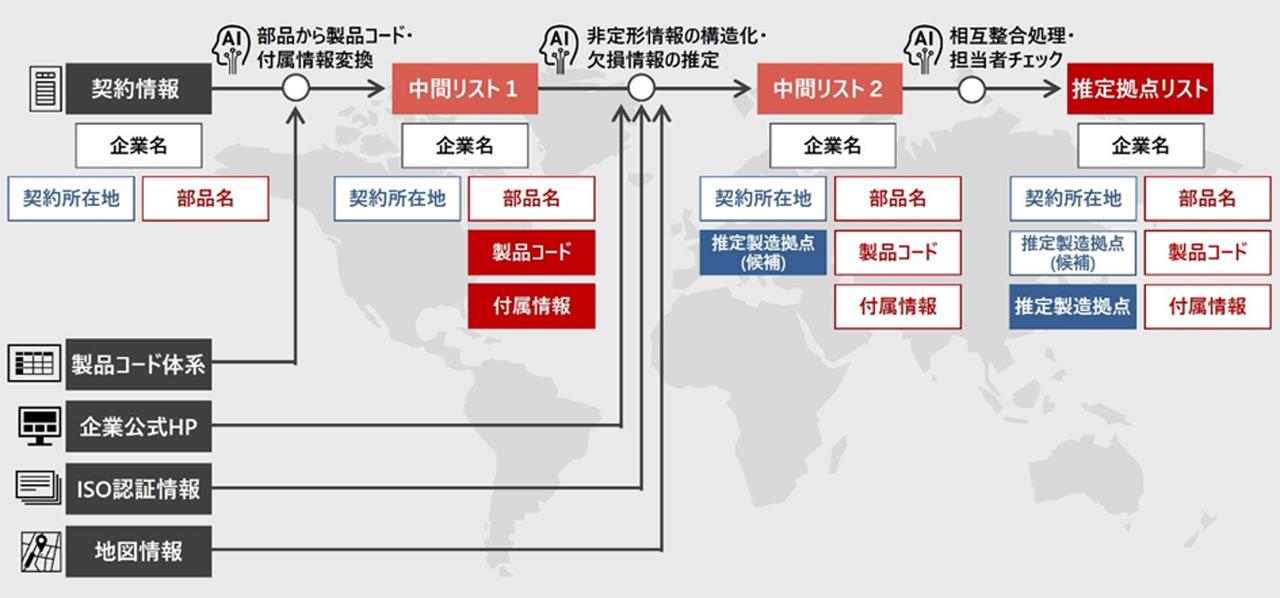
企業情報の分布図(青点が拠点の所在地を表す)
左図―本社:都市部に集中、右図―全拠点(製造拠点を含む):広範囲に分布
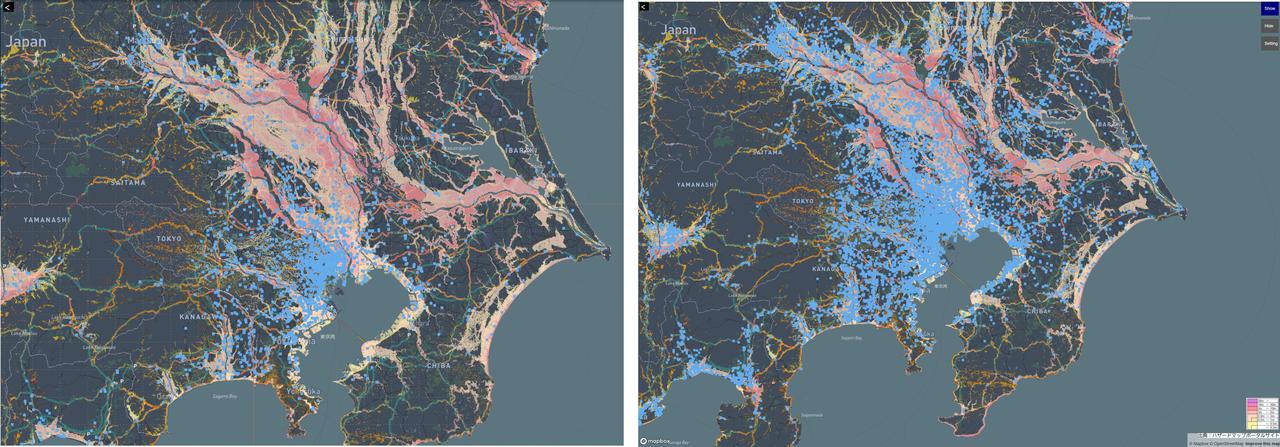
実際に使う担当者にとって、データから得られるインサイトを使いやすく提供する必要があります。また読み込むデータが膨大で起動に時間がかかってしまうようでは使ってもらえませんから、初期画面の描画で読み込むデータ量を減らし、起動をスムーズにするように作り込みました。部品ごとに推定した製造拠点を地図上に表示させることで、製造拠点が集中しているような状況を視覚的に把握できるように留意し、東大との共同研究による、ニュースや気象状況から整理した影響リスク予兆と照らし合わせて、台風や地震などのリスクがある地域に製造拠点が集中しているようなら、異なる地域の製造拠点から調達するような調整が可能になります。
もう1つ検討したのが、アプリケーションが示す情報そのものに信憑性があるか、システムがちゃんと動いているかという運用の側面です。きちんとした情報を提供できないと、使ってもらえなくなってしまいますから、使い続けてもらえるように意識してアプリケーションを作りました。
水品:何が根拠になっていて、いつのデータなのかを利用者に示す必要があります。また調達やBCP(事業継続計画)、財務、関税など、担当者の職務によっても見たい情報のポイントが異なります。どのユーザーにとってどんな画面が必要なのか、松田さんに整理して作り込んでもらいました。データを提供することはできても、実際の運用に必要なアプリケーションの作り込みについては考えが及んでいなかったことも多く、松田さんに色々指導してもらっているところです。
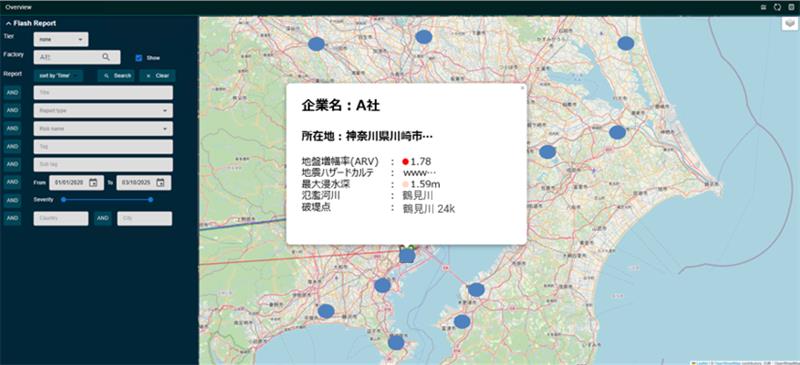
ディープインサイト技術を活用したサプライチェーンリスクの可視化例
実際にリスクと製造拠点の関係を可視化できたことで、自社が使っている部品がどこで作られているのかが把握でき、リスクとの関係に気づけるようになりました。検証の際にも、「調達先を最近変えたが、変更先も浸水区域内にあった。もう少し早くリスクとの関係を知りたかった」という声があったりして、推定製造拠点が可視化できることの意義は現場にも伝わっているようです。
精度向上とリスク回避法の提示機能の追加をめざす
松田:現時点では、サプライチェーンのどのあたりにリスクが高いかを地図上でわかりやすく表示できるようにアプリケーションを作っています。今後は、リスクと製造拠点の表示だけではなく、現状のリスクに対してどのような対策が打てるかを提示する機能を付加していきます。調達先を具体的にどのように変えればいいかをアプリケーション側から提示する形です。さらにその先では、将来的なリスクの予兆についてもアプリケーションから示すことで、将来の調達先の検討にもつなげられると考えています。

水品:日立グループ内での検証で得られた推定率85%以上という精度は、6割を超えれば実用になるという当初の目論見からすると高いものです。それでも、テクニカルにはもっと精度を向上させていきたいと思っています。さまざまな業種で使ってもらい、ユーザーからのフィードバックを取り込んで賢くなっていくシステムとして、精度を高めていくことができるはずです。一方で、サプライチェーンのリスクマネジメントの視点からは、ようやく地理情報が高い精度で推定できるようになったところです。リスクを見るべき場所がわかるようになり、これからリスク予兆の推定や評価の取り組みに進めていく段階です。東大の先生方や社内のスペシャリストたちから地理情報とリスク情報のつなぎ方の知見をもらいながら、さらにデジタルオブザーバトリの価値を拡張していきたいと思っています。

松田知紘(Tomohiro MATSUDA)
研究開発グループ Next Research
デジタルオブザーバトリプロジェクト 研究員
宇宙の未来に夢を馳せた少年を研究者へと誘った名作
中学生時代から読んでいたスター・ウォーズの小説版(ジョージ・ルーカスほか、講談社)が、今でも印象に残っています。スター・ウォーズではいろいろな星の人や多くのロボットが登場し、未来の技術もたくさん使われています。多様性に満ちた世界観が提示されていました。未来の技術に興味を持つきっかけになった本であり、実際のロボットの開発に携わることになったときはスター・ウォーズのR2-D2やC-3POに思いを馳せて作っていました。エピソード4の「新たなる希望」は特に印象に残っています。最初に読んだころには夢物語だと思っていた世界が現実になっている部分もあって、今でも面白さを感じています。

水品圭汰(Keita MIZUSHINA)
研究開発グループ Next Research
デジタルオブザーバトリプロジェクト 研究員
専門を通じて、他のことも語れる研究者への憧れの源
「知の逆転」(NHK出版新書)をご紹介します。「二重らせん」構造を解明したジェームズ・ワトソン、言語学に大きな影響を与えた「生成文法」を提唱したノーム・チョムスキーなど、6人のインタビューをまとめた書籍です。以前からチョムスキーが好きで、生成文法を研究したいと思っていた高校3年生の時に出会いました。1人ひとりが著名な専門家でありながら、専門外にも深い関心と知見を持ち、さまざまなことを自分の専門に紐づけて語れることに感銘を受けました。そういう大人になりたいと思った本です。大学院では半導体の研究をしていましたが、巡り巡って今は生成AIに関わっていて、生成文法との縁を感じたりしています。
(撮影:服部 希代野)