グラフ構造、すなわちノード(グラフの頂点)とエッジ(頂点同士を結ぶ辺)を用いてデータを表現する構造のデータベース(グラフデータベース)に対する再帰問い合わせは、複雑な関係を正確にたどれる一方、探索範囲が広がりやすく処理時間が増大しやすいという課題を抱えてきた。そこで日立製作所 研究開発グループは、東京大学と共同で、従来の「広く読んで後で絞る」方式に対し、「不要な領域は読み込まない(プルーニング*1する)」という発想に転換する新技術「動的プルーニング技術」を開発した。データベースなどへの検索要求(クエリ)実行中に探索範囲を動的に絞り込むことで、製造業やヘルスケア分野などで実用的な応答性能を実現する。データ&ナレッジマネジメント研究部の西川記史主任研究員と高尾大樹研究員に、開発の経緯から今後の応用までの取り組みを聞いた。
*1 プルーニング:機械学習モデルから不要な要素や冗長な要素を削除するプロセス
学生時代からデータベースの研究を続ける2人の研究者
西川:学生時代はオブジェクト指向データベース、つまりデータと処理を一体化して管理するデータベース手法、そして研究室に入ってからはそれに加えてハイパーテキストの研究に携わりました。修士課程修了後に就職先としてデータベースの研究を続けられる会社を探したのですが、国内にはそのような企業がほとんどなかったのです。そんな時たまたま「日立なら研究開発部門でデータベースに関わる仕事ができるらしい」ということを知り、アプローチしてみようと考えたのです。商用で使えるRDB(リレーショナルデータベース*2)は普及していましたが、それらは主に大企業・基幹系向けで誰もが手軽に使えるものはまだない時代でしたね。
*2 データを表(テーブル)形式で管理し、行と列の関連性によってデータを構造化するシステム。SQL(Structured Query Language)などを使用して、複数のテーブルを関連付けさせることで、データの操作・抽出・検索を行う。高い整合性と信頼性が確保できるため、銀行システムなどの勘定系や業務アプリケーションなどで利用されている。

日立製作所 研究開発グループ Digital Innovation R&D デジタルインフライノベーションセンタ データ&ナレッジマネジメント研究部 主任研究員・西川 記史
入社してからは、データベース関連でさまざまな仕事をしてきました。最初の3年ぐらいはオブジェクト指向データベースの製品開発、その後ネットワーク関連の研究に従事し、さらに米国にある日立のグループ会社に出向しました。帰国後は事業部門でリレーショナルデータベース管理システム(RDBMS)を開発、そして2003年ごろから東京大学とお付き合いがはじまり、国の研究開発プロジェクト(国家プロジェクト)に関わるようになり、そのご縁で、東大の博士課程コースに所属しデータベースとストレージの関係の研究で学位を取得しました。さらに米国のグループ会社でビッグデータの研究開発に従事し、その後、再度東大と共同で国家プロジェクトに取り組んでいます。今回の動的プルーニング技術の開発は、その国家プロジェクトで獲得した成果の一つです。
高尾:私は大学院に進学するタイミングで大学にできたばかりの情報学系を専攻しました。所属したのはデータベース系の研究室でしたが、修士課程までは自然言語処理の研究に取り組んでいました。研究の道に進むことを決意し、博士課程進学時に教授の勧めでデータベース分野に専攻を変更し、博士課程を修了して就職を考えるときも、データベース系の研究を前提にして探していたところ、その頃参加していた学会に日立がスポンサーとして参画していたことから興味を持ち、日立ならばデータベースの研究ができそうだと考え、就職先に選びました。

日立製作所 研究開発グループ Digital Innovation R&D デジタルインフライノベーションセンタ データ&ナレッジマネジメント研究部 研究員・高尾 大樹
入社以降西川さんのチームで、データベース系の研究をしています。配属時にはすでに動的プルーニングの研究が始まっていたので、評価実験や文献調査のお手伝いをするところから仕事が始まりました。現在は、その動的プルーニングをより使いやすくするための研究テーマに取り組んでいます。
グラフデータベースの再帰問い合わせの遅さが課題
西川:動的プルーニング技術の開発のきっかけは、データベースを産業分野で活用できないかと考えていた頃に遡ります。グラフ構造データは、ノードとそれらを結ぶエッジによりネットワーク状になった、相互に複雑なつながりを持つデータ構造です。こうした構造のデータを管理するデータベースが「グラフデータベース」ですが、すでに産業界における分析業務では活用されていました。ところがこのグラフデータベースには、データ量が増加したりデータの階層が深くなると「検索が遅くなる」という致命的な弱点があったのです。ですからもっとグラフデータベースを活用していただくには、この「検索の遅さ」に対処する必要があり、そのための研究を本格化させた、というわけです。

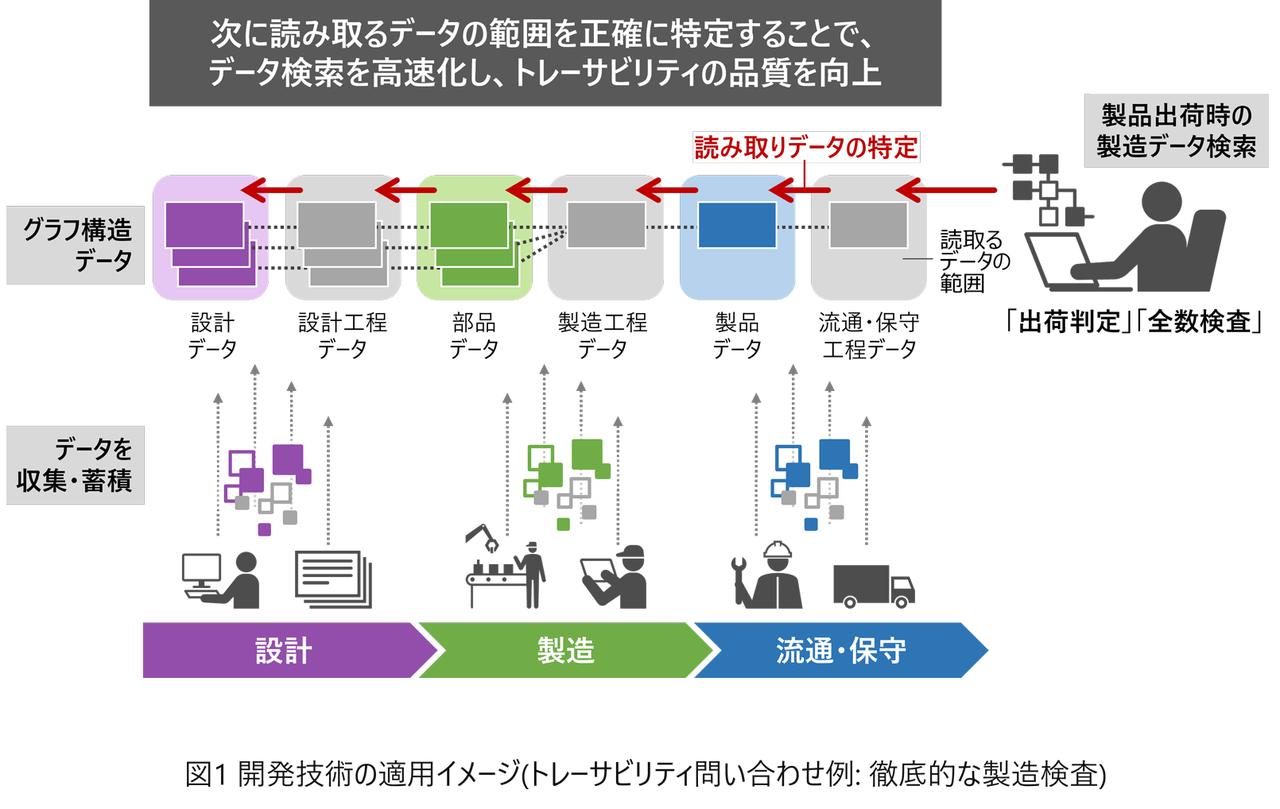
研究を本格化するにあたり、私たちは「再帰問い合わせ」に着目しました。再帰問い合わせとは、ある検索結果を次の検索条件として使い、関係をたどりながら繰り返し問い合わせを行うことで、再帰クエリとも言います。例えば製造業におけるグラフデータベースの活用例として、部品のトレーサビリティ(追跡可能性)があります。ある製品に対して、どのような部品がどのような順番で使われているかをトレース(追跡)するとき、製品から部品へと製造時の逆順にたどっていく必要があるわけです。そしてここで再帰問い合わせが使われます。製品には多くの部品が使われていますから、グラフ構造を再帰問い合わせでたどっていくために多くの時間を必要とするのはご理解いただけると思います。
例えば製品の出荷判定のタイミングで、構成している部品や、さらに「部品の部品」などがどのように使われているかを調べる必要がある場合、これまでは、検索に時間がかかるため、時間の制約上全数検査ができない部品については、一部の製品を抜き取ったサンプリング検査をせざるを得ないという状況がありました。しかしグラフデータベースの検索応答時間を短縮し、全数検査が可能になれば、不良品の出荷を抑えるといった実効的な効果が期待できます。そのため短時間で全数検査を実現する技術、つまりグラフデータベースの再帰問い合わせを実現できる技術が求められていたのです。

「不要なところは読み込まない」への発想の転換
高尾:トレーサビリティにおいて、ある製品を構成している部品すべてを探す例で、グラフデータベースに対する再帰問い合わせについて考えてみましょう。最終製品「A」について、構成する部品を検索していくプロセスです。
製品Aを構成する部品「B」「C」を検索し、さらに「B」を構成する「D」「E」を探し出し、「D」の構成部品である「G」「H」を見つけます。一方、部品「C」についても、構成部品の「F」を探し出します。再帰問い合わせでは、すべての部品の検索にグラフデータベース上の不要な領域も含めて広く探索してしまいます。「B」を見つけるときも、「G」や「H」を見つけるときも、ほぼすべての広い領域で経路を検索するため、時間がかかるのです。
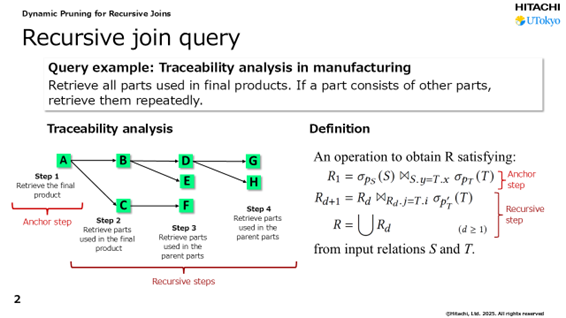
解決策として静的プルーニング(Static Pruning)という技術がありました。問い合わせのコンパイル(問い合わせ文を解析し、データベースが実行できる内部形式に変換する)時にフィルターベースでサマリー情報をあらかじめ用意することで領域を狭める方法です。ある製品の部品を検索するときは、値の範囲がここからここまでを検索すれば良いということを上位のステップに伝えて、検索の幅を狭めます。事前にクエリを最適化することで、検索時間を短縮できます。ただし、その静的プルーニングも、最初のうちは効果的に検索できるのですが、再帰問い合わせの段数が深くなると読む範囲が増えて時間がかかるようになる弱点がありました。

そこで日立と東大は、クエリの最適化を動的に実行できる「動的プルーニング(Dynamic Pruning)」を開発しました。あらかじめ最適化したフィルターを使うのではなく、クエリの実行中に対象となるデータベースの領域を絞り込めるようにするのです。「クエリの実行中に」というところがポイントです。再帰問い合わせのステップごとに、次に検索する必要があるデータベースの領域を動的に計算し、プルーニング、すなわち不要なデータの読み取りをスキップし高速化しようと考えたのです。
「A」の構成部品を検索するときは、ステップ1とステップ2の領域だけを検索します。「B」の構成部品を検索するときは、「B」につながったステップ3の領域だけを検索するといった具合です。再帰問い合わせの段数が増えると、劇的に検索範囲が少なく済むようになります。この方法で検索時間の短縮に大きな効果が見込めると考えたのです。
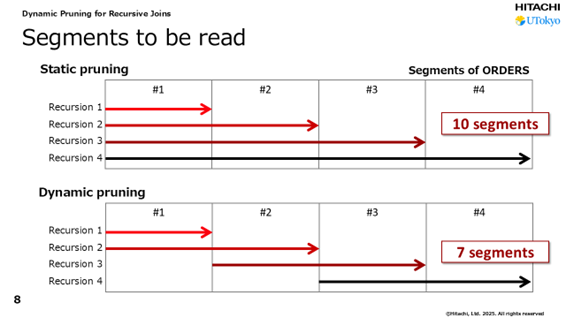
西川:実際に、Hitachi Advanced Database(HADB)*3というエンタープライズクラス、つまりデータセンターや大企業でのビッグデータ分析用に設計された高信頼性を誇る商用データベースを使って、動的プルーニングの実証を行いました。
動的プルーニングを使わない再帰問い合わせの実行時は80秒以上のレスポンス時間が必要でしたが、動的プルーニングを使うと、レスポンス時間を2.7秒まで短縮することができました。約30倍の高速検索が可能になっていることがわかります。入出力のデータ量をトレースした結果でも、プルーニングを採用しない場合は95GBほどのデータ量でしたが、動的プルーニングを適用することで1.83GBまで減少しています。
*3 Hitachi Advanced Databaseは、内閣府の最先端研究開発支援プログラム「超巨大データベース時代に向けた最高速データベースエンジンの開発と当該エンジンを核とする戦略的社会サービスの実証・評価」(中心研究者:喜連川 情報・システム研究機構 機構長/東大特別教授)の成果を利用しています。旧称:Hitachi Advanced Data Binder
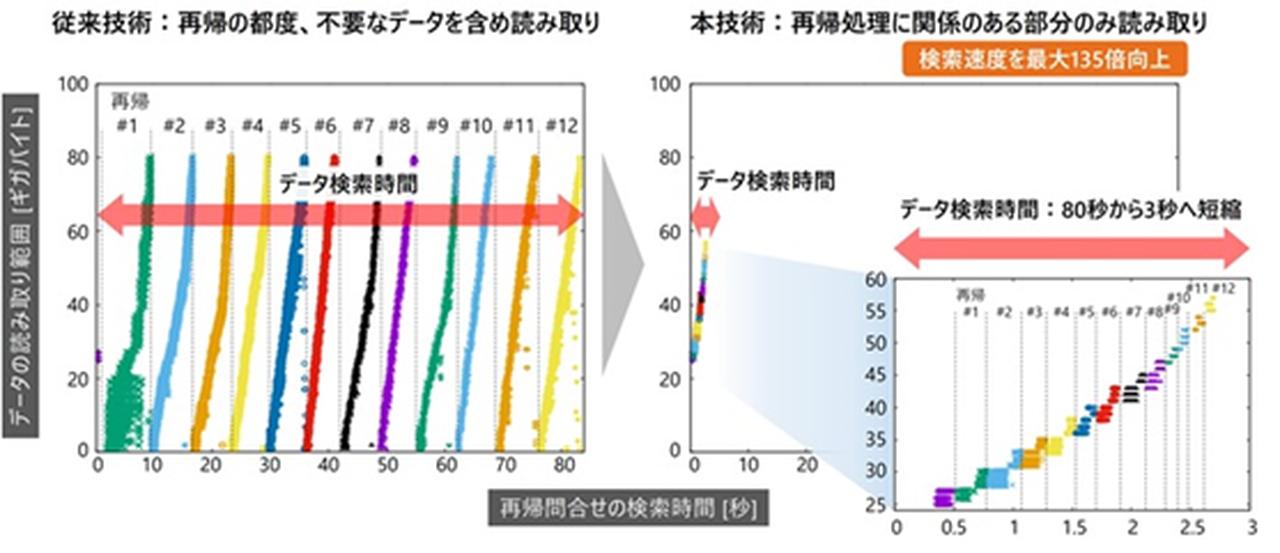
グラフを見ると、80秒以上にわたって12段の再帰問い合わせが行われていたところ、動的プルーニングにより3秒以内に領域を絞り込みながら問い合わせが完了していることがわかります。データベースの種類によって異なりますが、これまで最大で135倍の検索速度向上の効果が得られることがわかっています。特許も取得しました。
動的プルーニングをさらに強力なものにする技術
西川:東大の生産技術研究所の方にもこの研究に関わっていただきました。基本的なアイデアの提供をしていただきながら、日立からもアイデアを出して一緒に検討を進めました。定期的に対面での打ち合わせをするほか、必要に応じてオンラインで打ち合わせをさせてもらいました。論文は採択されるまで1年ほどの期間がかかっているのですが、その間に頂いたレビュアー指摘への対応の助言や実験結果の効果的なプレゼンテーションの指導などは本当に助かりました。論文の最終的な表現についても、東大の先生方に数多くのご助言を頂きました。
動的プルーニングにもまだ弱点はあります。例えば「データベースの構造次第で効能が変動する」という点です。製造業の例ではうまくいったのですが、条件が「範囲」で設定されていてセグメンテーション、つまり類似する性質を持つ小さなクラスタへの分割がきれいにできないようなケースでは効果があまり期待できない、ということもあり得ます。このような場合は事業部門に協力を仰ぎ、広範囲で動的プルーニングの効果が得られるようなデータベース構造に作り変えてもらうということもあります。
高尾:私はこれに関連して、この動的プルーニングをさらに強力なものにするため、さまざまなアプリケーションに適用できる前処理部分の技術を開発しています。複数次元のデータが使われるときに、セグメンテーションをどのような方法できれいな形にしていくか、という技術です。これにより動的プルーニングの効用が拡張していくはずです。

西川:高尾さんが研究している技術を適用できるようになると、さらに動的プルーニングの効果が得られる範囲が広がるでしょうね。このような新技術は、お客さまの要望に沿ってHADBなどの製品やサービスに適用していくことになるので、最終的には事業部門の判断に委ねる部分になりますから、彼らとのコラボレーションが極めて重要な技術、とも言えるかもしれません。
国家プロジェクトの研究で応用範囲を広げる
西川:商用データベースのHADBですでに動的プルーニング技術は稼働しています。導入すればすぐにご利用いただける状態になっています。これまでに製造系のお客さまでうまく使っていただいていますし、ヘルスケア分野での適用も進んでいます。今後有力なのは電力(送電)やAIなどの分野でしょうね。ここで動的プルーニングは大いに威力を発揮するはずです。
この技術は、東大との共同開発に加え、内閣府の国家プロジェクトである戦略的イノベーション創造プログラム(SIP)の第3期の課題としても研究開発を進めています。このプログラムの「統合型ヘルスケアシステムの構築」には15プロジェクトがあり、私たちはその中の「大容量医療データの高速処理・高効率管理・高次解析基盤の開発」(研究開発責任者:合田 和生 東京大学 生産技術研究所 教授)に取り組んでいます。狙いは「医療デジタルツインの構築」で、高速解析技術として動的プルーニング技術を適用する研究を進めています。
高尾:私自身は、動的プルーニング技術から離れた研究テーマに現在は主軸を移しています。生成AIの利用が広がる中で、非構造データを取り扱うことが増えているのはみなさんご承知の通りかと思いますが、一方で非構造データはRDBで扱うことが難しいという課題がありました。私は非構造データを高次元ベクトルに変換して管理することで、RDBの枠組みの中で取り扱えるようにする技術開発に取り組んでいます。このベクトルデータベースは、2026年春に学会で発表しました。
研究者にとっての日立とは

高尾:日立の研究開発グループでは、西川さんのようなベテラン研究者や、技術に精通した事業部門の方々と一緒に仕事ができますし、アカデミアの方からも多くの知見を得ています。毎日勉強することがいっぱいですが、やりがいを持って取り組んでいます。研究開発グループは大きな組織ですから、同期入社の研究者も多く、休みの日に仲の良い同僚と遊びに行ってプライベートから研究の話まで盛り上がっているのも楽しい点です。
西川:日立に入社して、いろいろなことを体験できたことに感謝しています。海外での研究活動は大きな収穫になりましたし、事業部門とのつながりが強い仕事をさせてもらったことも良い経験でした。研究者でありながら、展示会で説明するような経験も積めました。技術を開発するだけではなくて、お客さまと対話を重ねることで、どのように研究成果が社会に役立っていくのかを感じられるのは、研究者冥利につきますね。

西川記史(Norifumi NISHIKAWA)
日立製作所 研究開発グループ Digital Innovation R&D
デジタルインフライノベーションセンタ データ&ナレッジマネジメント研究部 主任研究員
データベースの原理から実装までを理解する
「Transaction Processing」(Jim Gray、Andreas Reuter 著、Morgan Kaufmann)に影響を受けました。1992年に出版されたデータベースの書籍で、入社3年目に事業部門に派遣されてデータベースエンジンの実装に携わるようになったときに教えてもらいました。この本を読み込んだおかげで、データベースの足回りがどうなっているかの原理から実装まで理解でき、現在までの研究につながっています。当時は英語版しかなかったので英語で読み通しました。今は日本語訳も出版されていますが、日本語版だと2冊になるので英語版がおすすめです。データベースの基本的なところを学んでいたから、ストレージとの連携などもできたのだと感じています。

高尾大樹(Daiki TAKAO)
日立製作所 研究開発グループ Digital Innovation R&D
デジタルインフライノベーションセンタ データ&ナレッジマネジメント研究部 研究員
データベースの理論を知りワクワク
思い入れがある書籍として「データベースシステム」(北川博之著、オーム社)を紹介します。修士課程から博士課程に進むときにデータベースへと研究テーマを変えることになり、教授自身が学生時代にお世話になった先生が書かれた書籍として、推薦されました。書籍中ではデータベースの管理技術を数学的にも議論されており、それまでデータベースはツールとしては扱っていただけでしたが、中身の理論が数学的にきれいに表現されていてワクワクしました。データベースというものが、学術的に見てもとても面白い世界だと感じ、この世界に踏み出すきっかけになった一冊です。理論的にデータベースの勉強をしたい人には、参考になると思います。
(撮影:服部 希代野)