データセンターやクラウドサービスにおけるデータ保存効率向上に向け、処理速度を約一桁向上
日立はデータストレージの効率化をめざし、深層学習を用いた新たな可逆データ圧縮*1技術を開発しました。この技術は、独自に開発した深層学習の層数に依存しない高速な推論モデルを採用しており、データ圧縮に必要となるデータ列のパターン*2を高精度に予測できることに加え、処理時間を大幅に短縮できます。その結果、従来の推論モデル方式と比べて、同等の予測精度を維持しながら、推論モデルの処理速度を約一桁向上できることを確認しました*3。本技術により、データセンターやクラウドサービスにおけるデータ保存効率を向上し、お客さまの経済的・環境的負担を軽減することが期待されます。
デジタルデータの増加に伴い、その保存コストはお客さまの重要な課題となっており、この問題に対処するため、多くの企業ではデータ圧縮技術を活用しています。従来の可逆データ圧縮技術は元のデータを完全な形で復元可能である一方、テキストや画像などのさまざまなデータの特性ごとに最適化されておらず、圧縮効率は限定的でした。そこで、データから学習し、データの特性ごとに最適化する深層学習を用いた圧縮技術が期待されています。しかし、従来の深層学習技術は計算時間が長く、ビジネス用途には不向きでした。
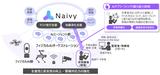
今回、日立は、深層学習モデルやデータストレージの知見を活かして、計算時間が深層学習の層数に依存しない高速な推論モデルを用いた新たな可逆データ圧縮を開発しました。具体的には、計算時間が長いことが課題であった推論モデルにおいて、各層における中間結果を層ごとに貯めて一括で計算することで、層の数が増えても計算時間が増えないように設計しました。これにより、推論モデルの計算時間を大幅に短縮することが可能となりました(図1)。
所定の条件下において、従来の推論モデル方式と本技術を比較したところ、処理速度が約一桁速く、同等の予測精度であることを確認しました。本技術により、データセンターやクラウドサービスおける膨大なデータを高速かつ効率的に保存でき、お客さまの経済的・環境的負担を軽減することが期待されます。
今後、日立は、データセンターやクラウドサービスを活用するお客さまとの連携を通じて、さらなる高速化に向けた研究開発を進め、本技術の実用化をめざします。
なお、本技術の一部は2024年11月にIEICE Transactions Onlineに掲載されました。

図1 推論モデル処理を一桁高速化する本技術と可逆データ圧縮処理の概要
(① 深層学習を用いた推論モデルによりデータ列のパターンを高精度に予測、②各層の中間結果を層ごとに貯め一括計算、
③深い層での計算頻度を削減し、層数が増えても処理量が増えない)
*1 可逆データ圧縮: データを圧縮しても情報を失わないデータ圧縮技術。圧縮されたデータを元の状態に完全に復元できるため、データの整合性が重要な場合に使用される。
*2 データ列のパターン: データ圧縮では、元データ列の各データポイント(例えば1ビットのデータに相当)について、過去のデータポイントから当該データポイントの出現確率を逐次的に高精度で予測することで、データを高圧縮できる。データ列のパターンとは、この予測されたデータポイントの出現確率を表す。
*3 データ圧縮を想定した自己回帰型の推論処理*4において、従来の高速トランスフォーマー方式*5は約1260万個のパラメータ、本技術で用いる推論モデルは約280万個のパラメータを用いた、ネットワーク構成等の条件下で比較。
*4 自己回帰型の推論処理: 現在のデータポイントを過去のデータポイントを入力として統計モデルにより逐次的に予測する処理。
*5 高速トランスフォーマー方式: データ圧縮やデータ生成で使われるトランスフォーマー方式の中で、線形型のアテンションにより計算量を減らし、高速に処理できるよう工夫されたモデル。
照会先
株式会社日立製作所 研究開発グループ